TECHNICAL REPORT
| Grantee |
Griffith University
|
| Project Title | Adversarial Machine Learning Attacks in Wireless Networks |
| Amount Awarded | USD 29,627 |
| Dates covered by this report: | 2023-01-01 to 2023-12-31 |
| Report submission date | 2024-04-08 |
| Economies where project was implemented | Australia |
| Project leader name |
Dr. Wee Lum Tan
|
| Project Team |
Dr. Ye Tao
A/Prof. Hui Tian
Prof. Alan Wee-Chung Liew
|
Project Summary
There has been an increased interest in the application of machine learning in wireless communication networks in recent years, enabled by the advances in machine learning techniques and computational hardware resources. Driven by the various data characteristics of wireless communications (e.g. channel status, signal strength, noise power, traffic pattern), machine learning can be used to optimally tune the various wireless network parameters and hence optimize the network performance. However machine learning is also vulnerable to adversarial attacks. Malicious attackers can use the same data characteristics of wireless communications in order to design their attacks and tamper with the networks’ learning process or interfere with their network communications. These attacks can cause the wireless networks performance to degrade substantially. In this pilot project, we have investigated adversarial machine learning attacks in Wi-Fi wireless networks using the reinforcement learning model. We have implemented models of the adversarial machine learning attacks in the ns-3 network simulator and evaluated the impact of these attacks on the network throughput performance. It is essential to better understand these adversarial attacks to enable one to design effective countermeasures against them and therefore lead to the safe adoption of machine learning applications in wireless networks.
The main activities conducted in this project include
- extensive literature survey to understand current works in applying reinforcement learning (RL) to Wi-Fi rate adaptation algorithms
- design, implementation and evaluation of our own RL-based Wi-Fi rate-adaptation algorithm (named ReinRate) in the ns-3 network simulator
- extensive literature survey to understand current works in adversarial machine learning attacks in wireless networks
- design, implementation and evaluation of an adversarial machine learning attack model that can negatively impact the throughput performance of Wi-Fi network nodes in the ns-3 network simulator
The code base developed in this project (both the ReinRate and adversarial attack works) are available for download on GitHub:
These are publicly available to enable other researchers in the world to extend on our work and further the knowledge development on reinforcement learning models as applied to Wi-Fi wireless networks.
We have also written a paper on the ReinRate rate adaptation algorithm which has been accepted and will be presented in the 2024 IEEE Wireless Communications and Networking Conference (WCNC) in Dubai. The paper is titled "A Reinforcement Learning Approach to Wi-Fi Rate Adaptation Using the REINFORCE Algorithm" and will be available for download from IEEE Xplore digital library.
Table of Contents
- Background and Justification
- Project Implementation Narrative
- Project Indicators
- Project Review and Assessment
- Diversity and Inclusion
- Project Communication
- Project Sustainability
- Project Management
- Project Recommendations and Use of Findings
- Bibliography
Background and Justification
Advancements in technology have led to the widespread deployment of wireless networks in our homes, office buildings, industrial plants, and IoT-connected smart cities. Wireless networks such as Wi-Fi are commonly deployed by network operators and organisations to provide the wireless last-hop Internet connectivity to users. However it is very challenging to design and configure these wireless networks to operate optimally due to the multitude of wireless network parameters to tune (channel selection, transmission power, modulation rate, coding, etc.), the dynamically changing wireless environment, the different capabilities of heterogeneous end-devices (smartphones, sensors, laptops, vehicles, etc.) and the need to satisfy the quality-of-service requirements from end-users. There is a need for a flexible and adaptive network architecture that is capable of cognitive behaviour wherein the network nodes are intelligent and can sense the network environment, process the collected data and compute the optimal policy to employ that will maximise network throughput and energy-efficiency.
Recently there has been increasing interest in designing self-organising, self-aware, intelligent wireless networks via the application of machine learning, in particular utilising the deep neural network technique. Machine learning enables network nodes to actively learn the state of the wireless environment, detect correlations in the collected data, and make predictions or take actions to optimise network operations and make efficient use of the limited wireless spectrum resources. For example, network nodes can train a machine learning model over a period of time using various wireless network statistics, e.g. channel state information, signal strength, traffic patterns, etc. Using the trained machine learning model, network nodes can predict future channel availability status, and make their transmission decisions by adapting to the spectrum dynamics. Integrating machine learning into the operation of wireless networks results in an intelligent system that learns from previous experience in order to make optimal decisions that maximise network performance.
However the use of machine learning in wireless networks is a double-edged sword. While it can help optimise network operations, it is also vulnerable to adversarial attacks. These attacks can be classified into three categories:
- Exploratory (or inference) attacks – the adversary trains itself to understand or infer how the nodes in the network will behave based on the captured wireless data
- Evasion attacks – the adversary attempts to trick the network nodes into making mistakes in their decisions
- Poisoning (or causative) attacks – the adversary tampers with the network nodes’ learning process by injecting incorrect training data
These adversarial machine learning attacks in wireless networks can interfere with the network nodes' data transmissions or cause them to make incorrect decisions. For example, an adversary can train its machine learning model to be functionally equivalent to the one at the transmitter, and then launch attacks (e.g. sends jamming signals to the receiver) when it predicts that the transmitter will transmit data to the receiver. Alternatively the adversary could also launch evasion attacks whereby it fools the transmitter to think that the wireless channel is busy and thereby prevent it from transmitting its data. These adversarial attacks are different from the more common brute-force jamming attacks which basically disrupt wireless communications by generating a high-power noise at all times. These adversarial attacks are more intelligent in that the adversary tries to remain imperceptible to the network nodes and minimise its energy consumption by only launching attacks when it predicts a valid transmission is about to happen. These attacks can have a significant impact on the network performance, e.g. reduced spectral efficiency, increased energy consumption on the legitimate network nodes, etc.
In this project, we have investigated and proposed the use of a reinforcement learning (RL)-based algorithm to learn and adapt to the dynamic, time-varying characteristics of the Wi-Fi network. Through extensive ns-3 simulations, we show that our proposed RL approach can achieve superior network throughput performance compared to traditional strategies that are in use in existing Wi-Fi networks. We have also investigated and proposed the use of a RL-based adversarial attack model that can intelligently interfere with the network communications in Wi-Fi networks in an energy-efficient manner. Through extensive ns-3 simulations, we show that the proposed adversarial attack model can reduce the network throughput performance with less energy expenditure, compared to a simple heuristic attack approach. Our work will help to better understand the vulnerabilities of machine learning to adversarial attacks and lead to the safe adoption of machine learning in wireless networks. The proposed models and algorithms in this project have been implemented and evaluated in the ns-3 environment, a widely recognized discrete-event network simulator. Unfortunately due to time limitations, we did not manage to complete the implementation of the proposed models and algorithms in the software-defined radio (SDR) testbed. We intend to continue with the implementation work on the SDR testbed, and share our results with the wider networking community through open-source release and technical publications.
Project Implementation Narrative
A Reinforcement Learning Approach to Wi-Fi Rate Adaptation Using the REINFORCE Algorithm
Introduction
The continuous evolution of Wi-Fi standards, encompassing IEEE 802.11n (Wi-Fi 4), IEEE 802.11ac (Wi-Fi 5), and the recent IEEE 802.11ax (Wi-Fi 6), has heralded the introduction of multifaceted configuration parameters in both the physical (PHY) and medium access control (MAC) layers. It is very challenging to tune these parameters to achieve optimal network performance due to the dynamically changing wireless environment, varying network interference and traffic load conditions, the different capabilities of heterogeneous end- devices and the need to satisfy the Quality-of-Service (QoS) requirements from end-users. Central to the efficient operation of these networks is the Modulation and Coding Scheme (MCS) parameter, which plays a pivotal role in determining the network throughput.
Rate adaptation is the mechanism used to select the best MCS or data rate to use in each data frame transmission. While selecting a high data rate may lead to higher network throughput, it may also result in higher probability of a failed transmission in poor channel conditions. On the other hand, selecting a low data rate leads to higher probability of a successful transmission but results in lower channel utilisation. Therefore selecting the best data rate in varying wireless channel conditions is crucial towards optimising network performance. Due to the dynamic wireless channel and traffic load conditions, determining the optimal data rate to use in the rate adaptation mechanism is very challenging. Traditional algorithms such as Minstrel [1] and Minstrel High Throughput (HT) [2] exhibit limitations, especially in rapidly changing environments. The need for agile, responsive, and adaptive algorithms becomes paramount in such settings.
Enter the realm of Machine Learning (ML), specifically Reinforcement Learning. Reinforcement learning is a branch of machine learning that focuses on developing models capable of making intelligent decisions through interactions with an environment. In reinforcement learning, the agent learns from the environment in several ways. Firstly, it learns the state of the environment, which represents the current situation or configuration. The agent also learns the available actions it can take in each state. By taking actions and observing the subsequent state transitions, the agent learns the dynamics of the environment, understanding how its actions affect the state transitions. Furthermore, the agent receives feedback from the environment in the form of rewards or penalties. These rewards provide information about the desirability of the agent's actions and serve as a basis for learning. Through trial and error, the agent learns to associate actions with favourable outcomes and adjusts its policy to maximize the cumulative reward over time.
Reinforcement Learning (RL) offers a potential avenue to develop algorithms that can learn and adapt to the dynamic, time-varying characteristics of wireless channels. Our research endeavors to harness the capabilities of RL to address the perennial challenge of optimal rate-adaptation in 802.11 wireless networks. In this project, we propose an innovative rate adaptation algorithm (named ReinRate) based on a reinforcement learning approach. Our proposed solution uniquely employs the REINFORCE [3] reinforcement learning algorithm, which is traditionally used in areas such as game theory and robotics, to the domain of rate adaptation. Our policy network architecture provides the flexibility to adapt to changing network conditions by exploring different actions and exploiting the optimal ones based on an epsilon-greedy policy.
Related Work
Reinforcement Learning (RL) has carved a niche in Wi-Fi rate adaptation, emphasizing the paradigm of experiential learning to optimize wireless communications. Distinct from open-loop strategies such as Minstrel HT [2], RL-centric approaches leverage feedback loops to comprehend and act upon the ever-evolving changes in network parameters. In essence, RL methodologies immerse the algorithm within its operational environment, typically the wireless channel. The algorithm iteratively interacts with this environment, refining its strategies through a systematic trial-and-error approach to discover the optimal rate selection that optimizes a defined reward, often throughput.
In recent years, there have been several studies that employed RL in their rate adaptation algorithms. In [5], a deep reinforcement learning (DRL) based rate adaptation algorithm was proposed that considers the implications of network collisions in its reward function. The rate adaptation problem was formulated as a Markov Decision Process (MDP) and solved using the Deep Q-Network (DQN) algorithm. In [6], the authors investigated the use of DRL algorithms such as the natural actor-critic (NAC) and proximal-policy optimization (PPO) algorithms in rate adaptation to optimize network throughput. The work in [7] used the Q-learning algorithm in a reinforcement learning framework specifically tailored for the rate adaptation objective. The approach used the sender’s contention window size as the observed network state and the the number of acknowledged packets from receivers as the reward during discrete time intervals. In [8], the RL agent was trained based on the observed signal-to-noise-ratio (SNR) of received frames, with the product of the frame error rate and normalized MCS used as the reward function. A pivotal aspect of the approach was the use of a deep Q-learning network to train the reinforcement learning agent. In [9], the rate adaptation problem was first modeled as a 3D maze problem with the three major rate features MCS, MIMO mode, and bandwidth used as the coordinates of the 3D maze, and then solved using the Double DQN method. The majority of these works only evaluated their algorithms under scenarios with no network interference, while the works in [5] [9] only evaluated their algorithms in scenarios where both the sender and receiver nodes are being interfered with by other sender and receiver nodes. In contrast, in our work, we systematically evaluate the performance of our ReinRate algorithm under several network scenarios, with and without interference from competing senders. We also use the REINFORCE algorithm to solve the rate adaptation problem, in contrast to the use of the DQN algorithm in these works.
The REINFORCE Algorithm and Its Application in Rate Adaptation
The field of Reinforcement Learning (RL) offers a suite of algorithms tailored to optimize decision-making over time, catering to environments with stochastic dynamics. A seminal algorithm in this space is REINFORCE [3], which stands as a policy gradient method aimed at maximizing the expected cumulative reward by directly optimizing the policy. The REINFORCE algorithm operates under the principle that if an action taken in a particular state results in a positive outcome (or reward), the probability of choosing that action again in the future should increase.
In the context of rate adaptation for Wi-Fi networks, the REINFORCE algorithm is aptly suited to learn and determine the optimal MCS in a dynamic environment. In our application, the AP is transmitting data to the station, and hence the rate adaptation algorithm is running in the AP. The state is represented by the received signal strength (RSS) from acknowledgements (ACK) received by the AP, indicating the current wireless channel condition, in conjunction with the contention window size (CW), the current Modulation and Coding Scheme (MCS), and instantaneous throughput.
For each state, the set of possible actions corresponds to the available MCS indices. After transmitting a packet using a specific MCS (action), the AP receives an ACK, providing immediate feedback on the success or failure of the transmission. The difference in throughput from its theoretical maximum based on the chosen MCS becomes the reward signal, guiding the algorithm’s learning process.
By leveraging the REINFORCE algorithm, our rate adaptation strategy iteratively updates its policy based on the observed rewards. This continuous learning process ensures that the AP consistently selects an MCS that maximizes the throughput, catering to the dynamic variations in the wireless channel. In essence, by applying REINFORCE to rate adaptation, we harness the algorithm’s capacity to learn optimal strategies from raw feedback, enabling our Wi-Fi networks to achieve higher efficiencies, even in fluctuating channel conditions.
The architecture of our algorithm is shown in Figure 1 (Algorithm 1), consisting of a PolicyNetwork class to generate action probabilities through a softmax-activated fully connected network, and a REINFORCEAgent class employing an epsilon-greedy strategy for action selection. The update function calculates and normalizes cumulative returns at each timestep, computes policy loss, and backpropagates it to update the policy network via optimization.

Observation: In our proposed architecture, the observation or state (St) is characterized by several key variables obtained from the network dynamics. These include the RSS of the ACK frames at the AP, the current contention window size, the current MCS and throughput. The RSS provides a real- time assessment of the wireless channel condition at time t, denoted as RSSt. Therefore, incorporating all these variables, the observation St can be formalized as:
St = f (RSSt, CWt, MCSt, TPt)
where f (.) is a function that amalgamates RSS, contention window size (CWt), the current MCS (MCSt), and throughput (TPt) into a state representation.
Action: The action (At) in our framework refers to the selection of the MCS for the data packets. Using the REINFORCE algorithm, the system adaptively selects an action given the current state, formalized as:
At = g(St)
where g(.) is the policy function derived from the REINFORCE algorithm that dictates the action to take given the current state of the network.
Reward: The reward function (Rt) in our proposed system is formulated to encourage actions that lead to the maximization of the current throughput in the network. The system grants higher rewards when actions result in elevated throughput and correspondingly, assigns lower rewards when actions result in lower throughput. We lookup the corresponding theoretical maximum throughput values for the eight MCS indices, based on the channel bandwidth and Wi-Fi standard (802.11n). This provides an indicator of the discrepancy between the current network throughput and the theoretical maximum throughput. The theoretical maximum throughput can be defined as MaxThroughput:
MaxThroughput = lookup(MCSIndex, ChannelBW)
In this formulation, MCSIndex is the Modulation and Coding Scheme index and ChannelBW signifies the channel bandwidth. The reward Rt, considers the ratio of the actual throughput (ActualThroughput) achieved by the network to the MaxThroughput. It is computed as:
Rt = (MCSIndex/7) × (ActualThroughput/MaxThroughput)3
Here, (MCSIndex/7) encourages a higher MCS choice. A metric approximating 1 signifies that the network’s operation is in close alignment with its maximum potential. Conversely, a lower value of Rt suggests that the network’s throughput capacity might not be fully utilized. Thus the reward function encourages the system to adapt the transmission rate towards the theoretical maximum throughput, hence improving the overall network performance.
Simulation Environment: Simulations and evaluations in our research are conducted within the ns-3 environment, a widely recognized discrete-event network simulator. A significant part of our setup is the integration of ns3-ai [10], a reinforcement learning gym. Our rate adaptation algorithm operates within this gym. The variables required for observation, such as RSS, current contention window size, MCS, and throughput, are collected in ns-3 and then written into a shared memory chunk accessible by ns3-ai. This seamless integration of ns-3 and ns3-ai establishes a bi-directional communication, providing a real-time interface for the reinforcement learning model.
Training: The policy network in our architecture takes the current state Stas its input and generates corresponding output actions. The subsequent MCS selection is made utilizing an ε-greedy policy. Under this approach, the agent predominantly selects actions that it perceives to be optimal, or ’greedy’, doing so with a probability of 1 − ε. However, to ensure a degree of exploration and facilitate convergence to an optimal policy, the agent also selects actions randomly with a probability of ε. The procedure for collecting environment observation values and selecting the MCS unfolds as follows in our proposed architecture. After every 20 packets transmitted from the AP, the system collects and calculates the environment observation values from ns-3. These observation values are then relayed to ns3-ai, which determines the next MCS. The newly determined MCS is then applied to the forthcoming batch of packets scheduled for transmission from the AP.
Experimental Evaluation
In this section, we outline the experimental framework established for the purpose of evaluating the effectiveness of our proposed rate adaptation algorithm ReinRate. The focus of our experimental evaluation lies in comparing ReinRate with existing rate adaptation algorithms, specifically the Minstrel HT [2] and the Ideal [4] algorithms. The primary metric under consideration for our evaluation is the network throughput.
A. Experiment Settings
Figure 2 (Table I) summarizes the experiment settings used in our ns-3 simulations, where the AP is transmitting traffic to the station that saturates the wireless link throughout the simulation duration. The parameters used by our REINFORCE-based rate adaptation algorithm are shown in Figure 2 (Table II).

B. Baseline Models
The baseline models for our experiment consist of the Minstrel HT and Ideal algorithms. Minstrel HT, a commonly used rate adaptation strategy, implements a statistical, sample- based approach to rate selection. The Ideal RA algorithm, in contrast, operates by maintaining a record of the Signal-to- Noise Ratio (SNR) of every received packet at each station, and transmitting this SNR back to the sender (AP) via an out-of-band mechanism. This SNR is then utilized to select an MCS, guided by a set of SNR thresholds that are derived from a target Bit Error Ratio (BER) and MCS-specific SNR/BER curves.
C. Network Topologies
Our experimental evaluation is conducted under five distinct topology settings, intended to thoroughly evaluate the performance of our proposed algorithm in various scenarios with and without network interference. Figure 3 shows the topological settings for these five scenarios.
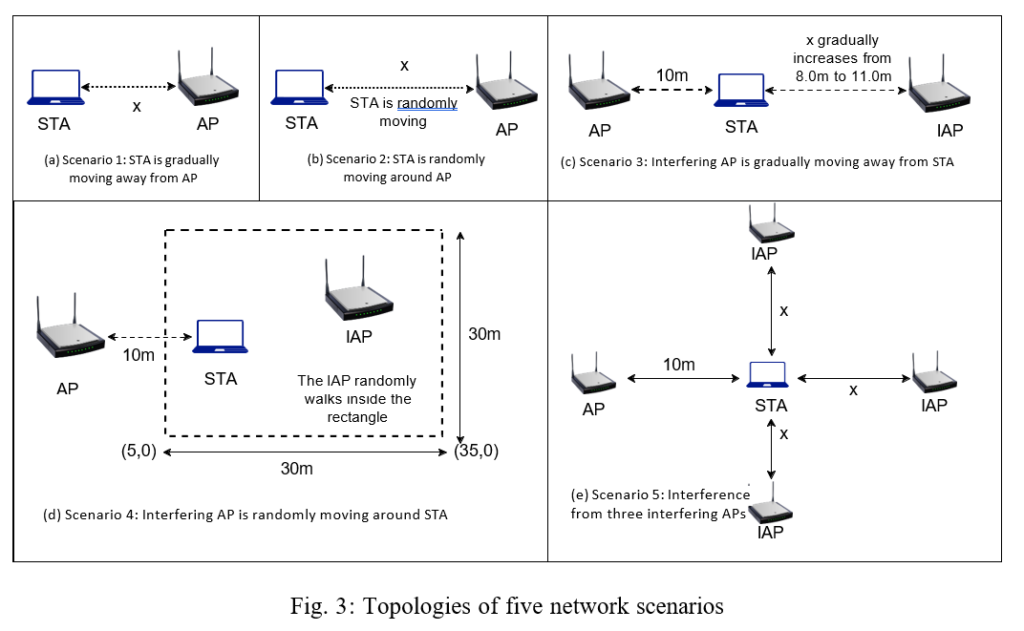
Scenario 1: Constant Moving: The initial topology in Figure 3a shows a single Access Point (AP) and a single station (STA) positioned x meters apart. To simulate deteriorating channel conditions and evaluate the responsiveness of our algorithm to changes in channel quality, the station is steadily moved away from the AP over a period of 80 seconds. The movement speed is set at a pace of 0.5 m/s to ensure gradual changes in the channel conditions.
Scenario 2: Random Walk: The second topology in Figure 3b makes use of a Random Walk mobility model, simulating a more dynamic and unpredictable wireless network scenario. In this model, the station moves randomly within a predefined linear line, introducing significant variations in channel conditions. This scenario serves as a rigorous test for our rate adaptation algorithm’s resilience and adaptability. The mobility model used is ns3::randomwalk2dmobilitymodel, with the range of the linear line between 0 to 24 meters away from the AP. The speed of the station is maintained at a constant 3.0 m/s.
Scenario 3: 1 AP, 1 STA, 1 Interfering AP: In this configuration in Figure 3c, we deploy a single AP with a single station positioned 10 meters away from the AP. The Interfering AP (IAP) progressively moves away from the station, starting at 8m and extending to 11m. This basic configuration serves as a benchmark to assess the performance of the rate adaptation algorithm in the presence of network interference.
Scenario 4: 1 AP, 1 STA, 1 Interfering AP with Random Movement: In Figure 3d, the scenario employs a configuration similar to Scenario 3. However, the distinguishing feature here is that the IAP is set to move in a random walk pattern within a 30m x 30m rectangle.
Scenario 5: 1 AP, 1 STA, 3 Interfering APs, Static Scenario: In this setup shown in Figure 3e, we simulate a high-interference environment with four APs transmitting packets to a single station (STA). The goal is to study the response of the rate adaptation mechanism to increased interference levels. The AP, three Interfering Access Points (IAPs), and STA are arranged in a star formation, with the STA centralized. The variable x denotes the distance between the IAPs and the STA, evaluated for values ranging from 8.75m to 10m.
We conduct 20 simulation runs for each network scenario and throughput results are averaged over these runs. The five distinct network scenarios, incorporating both static and dynamic topologies, with and without network interference, enable a comprehensive evaluation of our proposed algorithm under a range of network conditions.
D. Discussion of Experimental Results
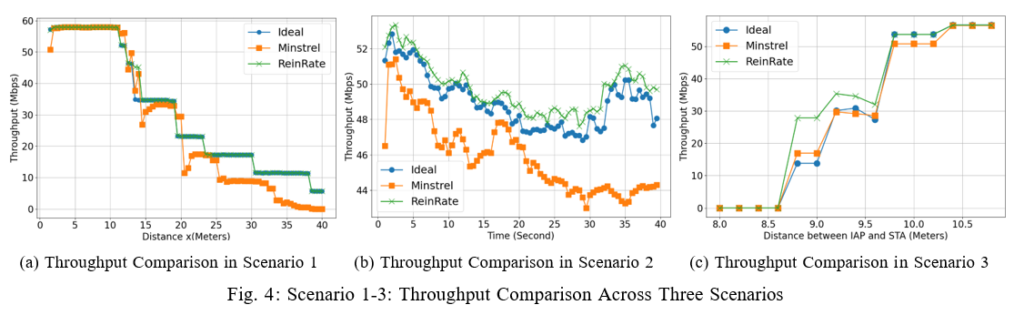
1) Scenario 1: Constant Moving: Figure 4a shows that the throughput performance decreases as the STA gradually moves away from the AP. We can see the distinct step declines in the throughput, corresponding to the different MCS levels chosen by the rate adaptation algorithms as the channel quality gradually degrades. Overall we can see that our proposed rate adaptation algorithm ReinRate tracks the throughput performance of the Ideal algorithm, and clearly outperforms the throughput performance of the Minstrel algorithm. ReinRate is shown to be better at adapting its performance in the presence of mobility-induced channel fluctuations, compared to Minstrel.
2) Scenario 2: Random Walk: Figure 4b shows that all three rate adaptation algorithms exhibit fluctuations in their instantaneous throughput values as the STA randomly moves around the AP. However, Minstrel demonstrated notably poorer overall throughput performance and greater throughput fluctuations compared to both the ReinRate and Ideal algorithms. ReinRate, in contrast, produced a better throughput performance, suggesting it is more capable to quickly adapt to rapid changes in channel conditions.
3) Scenario 3: One Interfering AP Moving Away from STA: In this setup, we positioned one AP and one STA 10 meters apart. This relatively short distance (in our simulations, the wireless channel is a lossy channel) was determined from the results in Scenario 1, marking the point where the throughput in all three algorithms begin to drop from the maximum throughput. We also have an Interfering AP (IAP) gradually moving further away from the STA as we measure the throughput of the AP’s transmission to the STA. Figure 4c shows that at a distance x = 8m, the strong interference from the IAP caused all of the AP’s transmissions to be dropped at the STA. As the IAP gradually moves away until x = 11m (therefore causing a reduction in its interference), we see a sharp increase in the throughput until it reaches the maximum throughput, indicating a swift recovery of the AP’s throughput. Throughout this range, ReinRate consistently outperformed the other two rate adaptation algorithms, indicating its ability to optimally select the MCS value in the face of network interference.
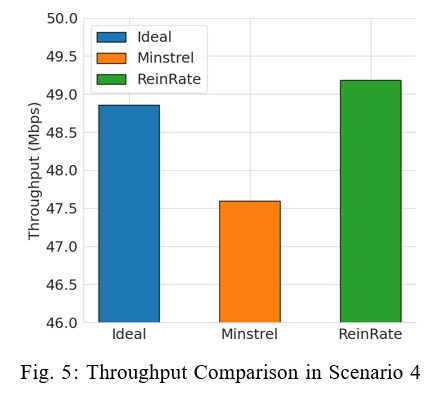
4) Scenario 4: One Interfering AP Randomly Moving Inside a Rectangle: This scenario is similar to Scenario 3, with the main difference being the Interfering AP is moving randomly within a 30m x 30m rectangular area. In this scenario, we want to evaluate the performance of the rate adaptation algorithms in dynamic network interference conditions. The results in Figure 5 shows the AP’s average throughput derived from 20 simulation runs. We see that ReinRate achieves the highest network throughput compared to the other two rate adaptation algorithms, indicating its superior performance in the face of dynamic network interference.
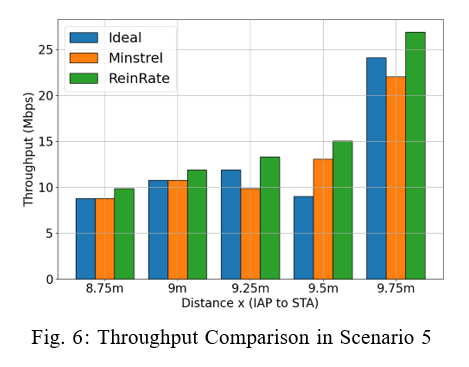
5) Scenario 5: 1 AP, 1 STA and 3 Interfering APs: In this scenario, three IAPs are symmetrically positioned at an equal distance x from the centrally located STA. We measure the AP’s throughput in the face of higher interference from multiple IAPs. Figure 6 clearly shows that ReinRate maintains a superior network throughput performance in comparison to the other two rate adaptation algorithms across the various interference distances (the effective interference range in our simulations is relatively short, similar to that seen in Scenario 3’s results). This indicates that compared to the other two algorithms, ReinRate is better able to optimally select the MCS value that results in higher throughput in conditions characterized by high network interference.
Conclusion
In this project, we have introduced a novel rate adaptation strategy for 802.11 wireless networks, named ReinRate, that is based on the REINFORCE reinforcement learning algorithm. ReinRate is designed to optimize the instantaneous network throughput, positioning it as a more adaptive and responsive solution in diverse network conditions. ReinRate’s adaptability comes from its capability to synthesize a broader range of network observations, incorporating metrics like the received signal strength, contention window size, the MCS and throughput. This comprehensive perspective ensures ReinRate’s aptitude for finely-tuned responses to network variations. With the REINFORCE algorithm at its core, ReinRate can iteratively discern the best rate adaptation actions corresponding to different network states. We have compared ReinRate’s performance with the traditional Minstrel and Ideal algorithms in diverse network scenarios, with and without network interference. Experimental results show that ReinRate consistently outperforms both algorithms, by up to 102.5% and 30.6% in network scenarios without interference, and by up to 35.1% and 66.6% in network scenarios with interference. Our results also show that ReinRate is able to quickly adapt to dynamic changes in channel conditions, compared to the two traditional algorithms.
Efficient Jamming in Wi-Fi Wireless Networks: A Reinforcement Learning Approach
Introduction
Following on from our work on ReinRate, we next design and develop adversarial attacks in Wi-Fi wireless networks using the reinforcement learning approach. In the adversarial attack model, we have an adversary that is able to monitor the victim’s (sender node) interaction with the receiver and the environment for a period of time such that the adversary can learn the victim node’s identifier, traffic sending pattern, transmission data rates, as well as the corresponding throughput and frame error rates.
Using these state environment observations, the adversary can launch an attack (i.e. sending a jamming frame) to interfere with the victim node’s transmissions at the receiver. If the attack is successful (i.e. the victim node’s frame is corrupted at the receiver), the victim node would not receive an ACK frame from the receiver, and the throughput performance of the victim node would be degraded. The objective of the adversarial attack is to negatively impact the reward of the ReinRate RL agent at the victim node, and hence trick the victim node’s ReinRate RL agent to select a non-optimal data rate for its future transmissions. As a result, these adversarial attacks can cause the wireless networks performance to degrade substantially.
Related Work
In recent years, there have been several works that have investigated adversarial machine learning attacks in wireless networks. In [11], the authors proposed an adversary that trained its machine learning model to be functionally equivalent to the one at the victim sender node, and then launch attacks (e.g. sends jamming signals to the receiver) when it predicts that the victim node will transmit data to the receiver. In [12], the work investigated an adversarial attack on the resource block allocation process in NextG radio access networks. The authors first proposed a reinforcement learning-based model to allocate resource blocks to to the requests of users with different QoS requirements. A reinforcement-learning based adversarial attack model was then built to select which resource block to jam, and hence reduce the performance of the network. The work in [13] considered the application of deep reinforcement learning (DRL) to dynamic channel access in wireless networks. An DRL-based jamming attacker was then designed that employs a dynamic policy and aims to minimize the victim's channel access accuracy. The DRL attacker agent observes the environment and learns the channel access patterns of the victim and performs jamming attacks. In contrast to these works, we propose an RL-based adversarial attack model that aims to reduce the network throughput to a specified throughput threshold level while being subjected to a limit on the maximum number of jamming packets sent per second. We systematically evaluate the performance of the RL-based adversarial attack model under different throughput thresholds and different maximum number of jamming packets sent per second.
The Adversarial Attack Models
A. Introduction
In our study, we concentrate on the adversarial manipulation of downlink Wi-Fi networks, where access points (APs) are engaged in transmitting packets to their associated stations (STAs). The easiest and most common adversarial attack is the brute-force jamming attack where the adversarial attacker is constantly sending jamming packets at all times. This is basically a denial-of-service attack as the victim AP (sender node) will be prevented from transmitting. However this approach is not efficient as it has a very high energy consumption and is also very easily detected.
In contrast to the brute-force jamming attack, we have an adversarial attacker that is able to monitor the victim AP’s (sender node) interaction with the station (receiver node) and the environment for a period of time such that the adversarial attacker can learn the victim AP’s identifier, traffic sending pattern, transmission data rates, as well as the corresponding throughput and frame error rates (see Figure 7). In particular, the adversarial attacker can sense/detect the energy level in the wireless channel and whenever it detects a transmission from the victim AP, the adversarial attacker can choose to launch an attack (i.e. send a jamming frame) to interfere with the victim AP’s transmissions at the station. If the attack is successful (i.e. the victim AP’s frame is corrupted at the station), the victim AP would not receive an ACK frame from the station, and therefore the throughput performance of the victim AP would be degraded.
In this project, we define a throughput threshold value (throughputthres), i.e. the throughput value that the adversarial attacker wants the victim AP's throughput to be reduced to. In other words, if the victim AP's current throughput is higher than the throughputthres value, then the adversarial attacker will send jamming packets in order to interfere with the victim AP's transmissions and hence reduce the victim AP's throughput to a value equal to or lower than the throughputthres value. The throughputthres value is selected so as to ensure the victim AP is still able to minimally transmit its data frames using low data rates. This helps to minimise the chances of the adversarial attacks being detected as well as minimise the energy consumption of the adversarial attacker, in contrast to the brute-force jamming attack.
B. Heuristic Attack Model/Approach
Based on the definition of throughputthres, we designed a simple heuristic attack model/approach whereby the adversarial attacker keeps track of the victim AP's current throughput. The heuristic attack approach works on a per-packet basis, i.e. for every packet sent by the victim AP, the adversarial attacker will compare the victim AP's current throughput with the throughputthres value. If (current throughput > throughputthres), the adversarial attacker sends a jamming packet to interfere with the victim AP's transmission, else it remains passive and continues monitoring the network.
C. Reinforcement Learning-based Adversarial Attack Model/Approach
We formulate the adversarial problem as maximizing the disruption caused to the network while ensuring the efficiency and stealthiness of the attack. This involves a strategic choice of when and how to jam the network, a decision process modeled as a sequential decision-making problem. The adversarial agent’s goal is to intelligently interfere with the packet transmissions, aiming to maximize the disruption in terms of reducing the victim AP's throughput to the targeted throughputthres value.
In the context of network security, the application of Reinforcement Learning (RL) for adversarial attacks, particularly jamming, introduces a dynamic and intelligent approach to disrupt network operations. The RL agent is equipped with a strategic policy, honed through the REINFORCE algorithm, to decide when and how to jam the network to maximize disruption while minimizing its own exposure and resource consumption. The RL agent employs a binary decision-making process for jamming, making it an unpredictable adversary. The decision to jam (send a jamming packet) or not (remaining passive) is based on the current network state, represented by a comprehensive 12-dimensional vector. This vector includes not only the current and throughputthres values but also the current transmission’s MCS encoding, which influences jamming efficacy, and a limit on number of jamming packets sent per second to optimize resource usage. The agent’s policy is optimized using the REINFORCE algorithm. This direct policy gradient method allows the agent to adjust its strategy based on the feedback (reward) from the environment. The reward provide information about the desirability of the agent's actions and serves as a basis for learning to associate the actions that lead to favourable outcomes, i.e. reducing the victim AP's throughput to the targeted throughputthres value. Hence the agent will adjust its policy to maximize the cumulative reward over time.
State Space: The state space, St, for the Reinforcement Learning (RL) agent is a 12-dimensional vector, encapsulating critical network parameters influencing decision-making and strategy. The components are:
• TPt denotes the current data transmission rate of the victim AP, reflecting real-time throughput dynamics.
• Throughputthres represents the targeted throughput rate, serving as a benchmark for the agent’s performance.
• MCSencode is a one-hot encoded vector capturing the current Modulation and Coding Scheme (MCS) in use, crucial for assessing the potential impact of jamming strategies.
• JPlimit sets a cap on the number of jamming packets sent per second, ensuring efficient utilization of jamming resources.
Action Space: The action space for the agent, denoted as At, encapsulates the decision to actively disrupt the network or to remain passive. It comprises:
• At= 1: The agent sends a jamming packet, actively intervening in the network traffic to disrupt communication.
• At= 0: The agent chooses inaction, refraining from sending a jamming packet, either to conserve resources or adopt a stealthier approach.
The action taken by the agent is a function of the current state, dictated by the policy derived from the REINFORCE algorithm, which can be formalized as:
At= g(St)
where g(.) represents the policy function that dictates the agent’s action based on the observed state of the network.
Neural Network Architecture: The policy, which maps states to actions, is represented by a neural network. The network takes the state as input and outputs the probability of taking each action. The neural network used in our policy representation is structured as follows:
• Input Layer: Consists of 12 neurons, corresponding to each dimension of the state space.
• Hidden Layers:
– First Hidden Layer: 64 neurons, using ReLU (Rectified Linear Unit) activation. This layer is responsible for capturing the nonlinear relationships in the data.
– Second Hidden Layer: 64 neurons, also with ReLU activation. It further processes the information from the first layer, abstracting higher-level features.
• Output Layer:
– Consists of 2 neurons, each representing the probability of taking one of the two possible actions (Jam/No Action).
– Uses a softmax activation function to output a probability distribution over the actions.
The network is optimized using backpropagation and gradient ascent with Adam as optimizer, with the objective of maximizing the expected return.
Reward Design: We use the REINFORCE algorithm, a policy gradient method to optimize the policy directly. The rewards are calculated by considering two factors: the difference of victim AP's current throughput and the targeted throughputthres value, and the "number of jamming packets sent". The "number of jamming packets sent" serves as a penalty factor.
The reward function R(·) is constructed from two primary components:
• Throughput Deviation Component (RTD): This component rewards the agent based on the absolute deviation of the current throughput from the targeted throughputthres value. It’s defined as:
RTD= −λ · |Tc− Throughputthres|
where λ is the weighting factor for throughput deviation. λ is by default set to 0.5. Tc denotes the current network throughput.
• Jamming Efficiency Component (RJE): This component penalizes the agent if the number of jamming packets sent exceeds a certain threshold, and is intended to promote efficient and strategic jamming. It’s defined as:
RJE= −µ · max(0, Pj− Pth)
where µ is the penalty factor for excessive jamming. µ is by default set to 0.5. Pj denotes the number of jamming packets sent by the agent, and Pth denotes the threshold for the number of jamming packets sent.
The overall reward function, representing the immediate effectiveness of the agent’s actions, is the sum of the aforementioned components:
R(s, a) = RTD+ RJE
D. Training
Figure 9 (Table II) shows the hyper-parameters settings of our RL-based attack model. The Adam optimizer, is employed to provide stability and accelerate the convergence of the agent’s policy network. Cross-entropy loss is selected for the binary action space. Training involves processing information in batches of 64 state-action-reward observations. The comprehensive training spans over 3000 episodes, is each initiated upon new packet transmission, and includes sequences of state-action-reward observations.
The policy network architecture comprises an input layer corresponding to state dimensionality, two 32-neuron hidden layers, and an output layer mapping to the action space. ReLU activation in hidden layers introduces non-linearity, while the output layer’s softmax function provides probabilistic action decisions. A learning rate (α) of 1e−4 ensures gradual updates to the policy network’s weights, complemented by an exploration rate (ϵ) of 1e−8 to balance strategy exploration and known action exploitation. The discount factor (γ) of 0.99 prioritizes long-term gains over immediate rewards.
E. Impact of Adversarial Attacks on the ReinRate Rate Adaptation Algorithm
In both the heuristic and RL-based attacks, successful jamming of the victim AP's transmissions will negatively impact the reward of the ReinRate RL agent at the victim AP, and hence trick the victim AP’s ReinRate RL agent to select a non-optimal data rate for its future transmissions. When this happens, the victim AP may take some time to recover from the non-optimal data rates, and as a result have lower network throughput for a period of time.
Experimental Evaluation
In this section, we evaluate the performance of the heuristic attack versus the RL-based adversarial attack.
A. Network Topologies
Our experimental evaluation is conducted under two distinct topology settings. Figure 8 shows the topological settings for these two scenarios.
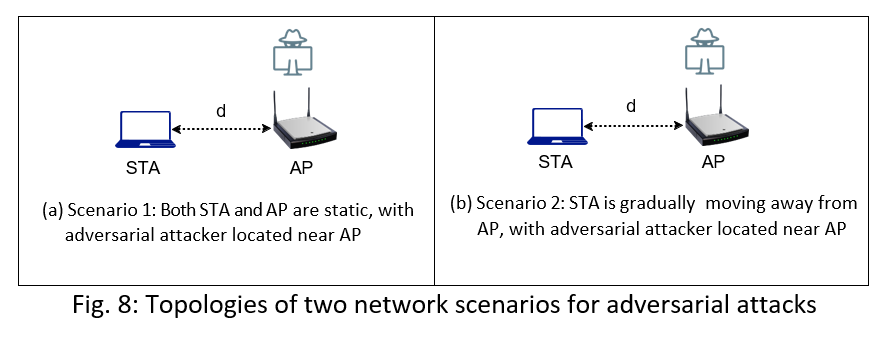
Scenario 1: Static Topology: The topology in Figure 8a shows a single Access Point (AP) and a single station (STA) positioned d=5 meters apart. The adversarial attacker is located near the AP in order to be able to overhear the AP's transmissions and reception of its ACK frames from the station. All three devices are static. This scenario is intended to evaluate the efficacy of the attack approaches under a constant environment.
Scenario 2: Constant Moving: The topology in Figure 8b shows a single Access Point (AP) and a single station (STA) initially positioned d=5 meters apart. The adversarial attacker is located near the AP in order to be able to overhear the AP's transmissions and reception of its ACK frames from the station. To simulate deteriorating channel conditions, the station is steadily moved away from the AP over a period of 40 seconds. The movement speed is set at a pace of 0.5 m/s to ensure gradual changes in the channel conditions. This scenario is intended to evaluate the efficacy of the attack approaches under gradually changing channel conditions.
B. ns-3 Experiment Settings
Figure 9 (Table III) summarizes the experiment settings used in our ns-3 simulations, where the AP is transmitting traffic to the station that saturates the wireless link throughout the simulation duration. We evaluate the performance of the heuristic attack and RL-based attack approaches under two throughputthres values: 20Mbps and 30Mbps. For the RL-based attack, we also investigate the impact of limiting the maximum number of jamming packets that are allowed to be sent per second. Specifically we investigate the RL-based attack performance when it is subjected to a limit of 500, 1000, 2000 jamming packets sent per second. This has an impact on the energy efficiency of the attacks as well as the probability of the attacks being detected, i.e. lower number of jamming packets sent per second would have higher energy efficiency and less chances of the attacks being detected. However lower number of jamming packets sent per second may not necessarily be able to reduce the network throughput to the targeted throughputthres values.
The primary metric under consideration for our evaluation is the network throughput and the number of jamming packets sent, which acts as an indicator of the energy efficiency in both attack approaches.
C. Discussion of Experimental Results
In the two scenarios, we show the maximum throughput achieved under the ReinRate rate adaptation algorithm without any attacks. This serves as a baseline result to show the impact of the adversarial attacks on the network throughput.
1) Scenario 1: Static Topology: Fig. 10 and Fig. 11 show the network throughput performance and the number of jamming packets sent per second, when the throughputthres value is set to 20Mbps and 30Mbps respectively.
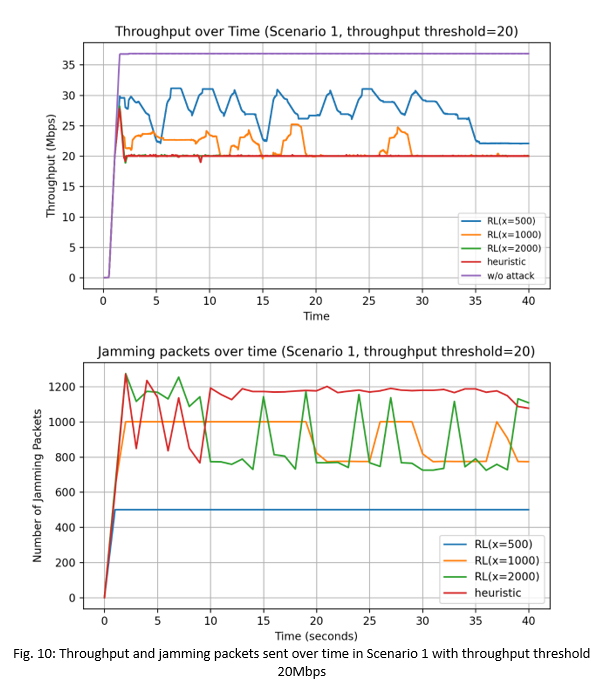
We see that without any attacks, the maximum network throughput with the ReinRate algorithm is 37Mbps. We also see that the heuristic attack is able to reduce the network throughput to the 20Mbps and 30Mbps threshold values respectively. With the RL-based adversarial attacks and with the throughputthres value set to the lower 20Mbps value in Fig. 10, we see that when the maximum number of jamming packets/sec is set to 500 and 1000 jamming packets/sec, the RL-based attacks are not able to reduce the throughput to the desired 20Mbps threshold value, indicating that the number of jamming packets sent is insufficient in both cases. It is only with the maximum number of jamming packets of 2000 packets/sec that we see the throughput is reduced to the targeted 20Mbps threshold value. We also see that with RL (x=2000), the maximum number of jamming packets sent per second is less than 1200 packets/sec, and is also lower compared that of the heuristic attack. This indicates that the RL-based attack is able to intelligently select when to send its jamming packets so as to limit the victim AP's throughput to the targeted throughputthres value in a more energy-efficient manner compared to the heuristic attack.
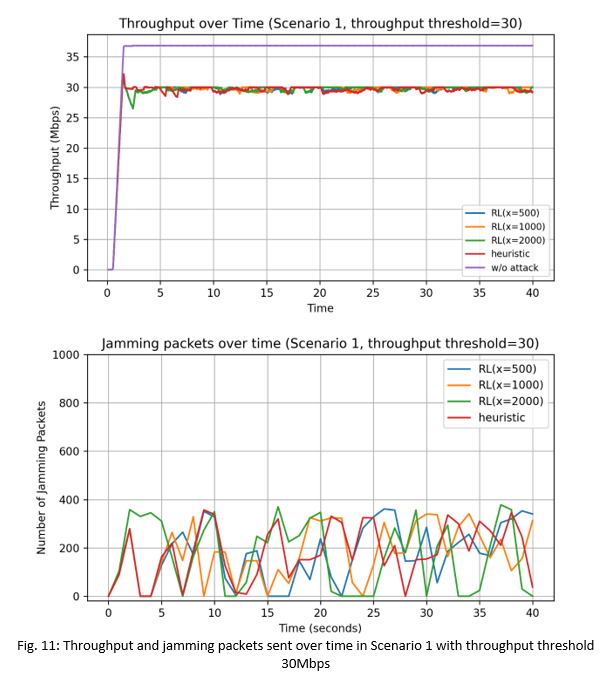
On the other hand, when the throughputthres value is set to a higher value of 30Mbps in Fig. 11, all three RL-based attacks (x=500, 1000, 2000) are able to reduce the throughput to the targeted 30Mbps threshold value. In this case, the maximum number of jamming packets required to achieve this is less than 400 packets/sec. Table IV (in Figure 14) shows the total number of jamming packets sent over the whole simulation duration. We see that for Scenario 1 across both targeted throughput values of 20Mbps and 30Mbps, the RL-based attacks used a lower total number of jamming packets compared to the heuristic attack. In particular the RL-based attack (x=2000) uses 19.6% less jamming packets compared to the heuristic attack in the throughputthres=20Mbps scenario, and uses 7.5% less jamming packets compared to the heuristic attack in the throughputthres=30Mbps scenario. This shows that the RL-based attacks are more energy efficient and are less likely to be detected, compared to the heuristic attack.
2) Scenario 2: Constant Moving: In Scenario 2, we see in Fig. 12 and Fig. 13 that without any attacks, the maximum network throughput with the ReinRate algorithm decreases as the STA gradually moves away from the victim AP. We can see the distinct step declines in the throughput, corresponding to the different MCS levels chosen by the ReinRate algorithm as the channel quality gradually degrades.
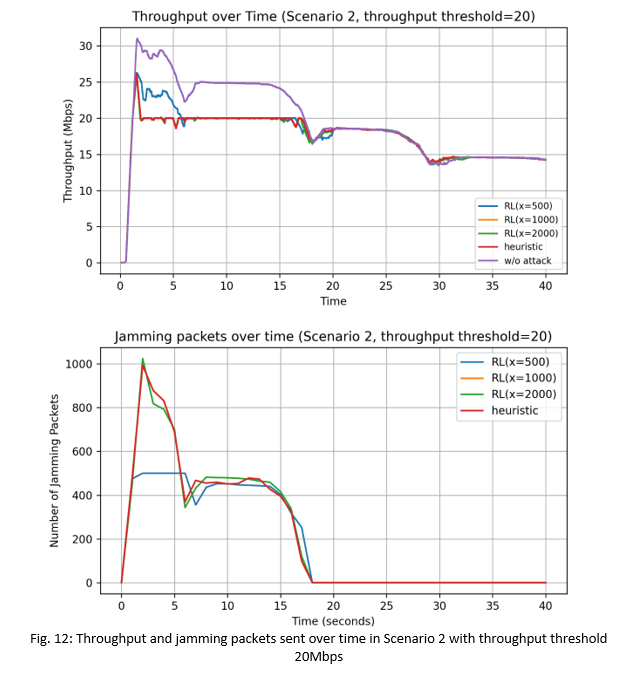
We also see in Fig. 12 that at time t=18s, the network throughput has dropped below the targeted thresholdthres value of 20Mbps due to the channel conditions between the STA and victim AP being unable to support a throughput performance higher than that. As a result, the heuristic and RL-based attacks also stopped sending jamming packets as can be seen in the bottom plot showing the number of jamming packets sent per second. Similar observations are seen in Fig. 13 with the target throughputthres value of 30Mbps.
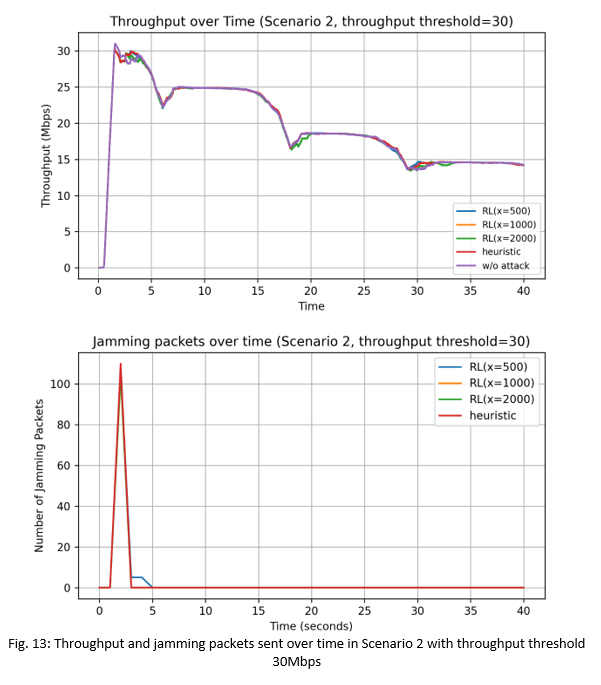
In Fig. 12, at the start until t=6s, the heuristic attacks and the RL-based attacks (with the exception of RL(x=500)) are able to reduce the network throughput to the targeted throughputthres value of 20Mbps, with the initial number of jamming packets sent equal to a high 1000 packets/sec. With RL(x=500), since it is limited to only 500 jamming packets/sec, it wasn't able to reduce the network throughput to the targeted value. However we see that after t=6s, the network throughput drops to the targeted value of 20Mbps. This is because the sending of the 500 jamming packets/sec in the first 5-6 seconds had negatively impacted the ReinRate algorithm at the victim AP, causing it to choose non-optimal low data rates for its transmissions, and thereby eventually reducing its network throughput to the targeted value of 20Mbps. In Fig. 13, we see that both the heuristic and RL-based attacks can easily reduce the network throughput to the targeted value of 30Mbps within the first 2s of simulation, with an initial sending of a low 110 jamming packets/sec being sufficient to interfere with the victim AP's transmissions.
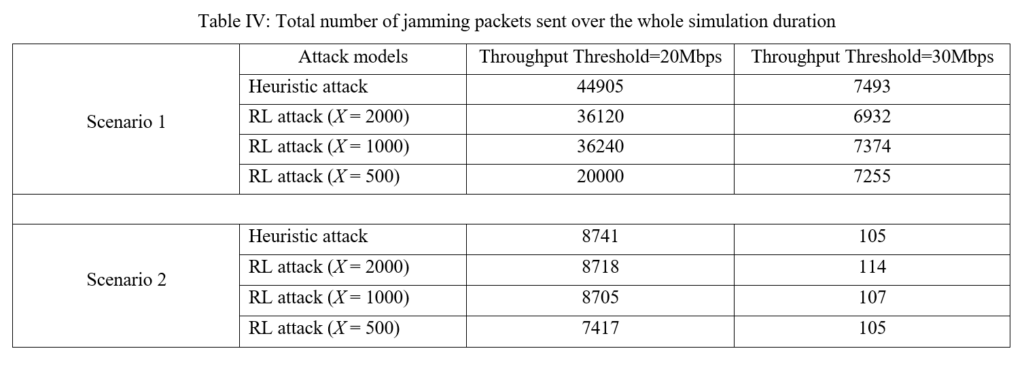
Table IV (in Figure 14) shows that the RL-based attacks used a lower total number of jamming packets compared to the heuristic attack in the throughputthres=20Mbps scenario, with most of the jamming packets sent in the first 18s of the simulation, again indicating that the RL-based attacks are more energy efficient and are less likely to be detected, compared to the heuristic attack. On the other hand, in the throughputthres=30Mbps scenario, the total number of jamming packets sent are similar for both the heuristic and RL-based attacks as it took only 2s for the attacks to effectively reduce the network throughput to the targeted value.
Conclusion
In this project, we have introduced a novel adversarial attack strategy in Wi-Fi networks. The objective of the adversarial attack is to negatively impact the reward of the ReinRate RL agent at the victim node, and hence trick the victim node’s ReinRate RL agent to select a non-optimal data rate for its future transmissions. As a result, these adversarial attacks will cause the network throughput performance to drop to a targeted throughput level. The adversarial attack strategy is based on the REINFORCE reinforcement learning algorithm, and intelligently decides when to send a jamming packet to interfere with the victim node's transmissions. The decision to attack or remain passive is based on the current network state incorporating metrics like the current network throughput, targeted throughput level, the current MCS encoding and the number of jamming packets sent per second. This ensures that the RL-based attack can effectively disrupt the victim node's transmissions while at the same time, minimize its own exposure and energy consumption. We have evaluated the performance of the RL-based attack and a simple heuristic attack approach in both static and mobile scenarios. The experimental results show that while both the simple heuristic attack and the RL-based attack can reduce the network throughput to the targeted throughput level, the RL-based attack uses up to 19.6% less jamming packets to achieve the task, thereby indicating that the RL-based attack is more energy efficient and is less likely to be detected, compared to the heuristic attack.
Key activities
Beginning of Project
| Activity | Description | #Months |
|---|---|---|
| Build models of adversarial machine learning attacks | Investigate machine learning vulnerabilities to adversarial attacks in wireless networks | 3 |
Middle of Project
| Activity | Description | #Months |
|---|---|---|
| Implement proof-of-concept | Build a software-defined radio (SDR) testbed and implement proof-of-concepts of adversarial machine learning attacks in wireless networks | 6 |
End of Project
| Activity | Description | #Months |
|---|---|---|
| Experiments on adversarial machine learning attacks | Evaluate practicalness and impact of adversarial machine learning attacks in wireless networks via extensive over-the-air experiments on the SDR testbed. Experiment results will be used to fine-tune the adversarial models. | 3 |
Project Indicators
| Indicator | Status |
|---|---|
| Literature Review | Completed |
| Models of adversarial machine learning attacks | Completed |
| Implement RL-based model of attacks | Completed |
| Wi-Fi experiments | Completed |
| Indicator: Literature Review Status: Completed Start and End Dates: January 1, 2023 to March 31, 2023 Description: - Literature review of machine learning models as applied to rate adaptation mechanisms in Wi-Fi wireless networks. - Literature review of adversarial machine learning models in Wi-Fi wireless networks Baseline:- Currently have a good understanding of the standard rate adaptation mechanisms in WiFi wireless networks - Some knowledge of machine learning models applied in WiFi wireless networks Activities: We have conducted an extensive literature review of reinforcement learning models as applied to rate adaptation mechanisms in WiFi wireless networks. We have also conducted an extensive literature review of current adversarial machine learning attacks in wireless networks. These related works are listed in the Bibliography section. Outcomes: Based on our literature review, we have identified the gap in the current research landscape and have designed, implemented and evaluated new algorithms to address the gap. |
| Indicator: Models of adversarial machine learning attacks Status: Completed Start and End Dates: April 1, 2023 to September 30, 2023 Description: - Design, develop and implement RL-based model of Wi-Fi rate-adaptation algorithm - Design and develop models of adversarial machine learning attacks in Wi-Fi wireless networks, specifically targeting the rate adaptation mechanisms Baseline:No models developed yet Activities: Using the REINFORCE algorithm, we have designed - a reinforcement-learning based rate adaptation algorithm (named ReinRate) for Wi-Fi networks - an adversarial machine learning attack model on the ReinRate algorithm Outcomes: The models that we developed will be implemented in the ns-3 simulator. |
| Indicator: Implement RL-based model of attacks Status: Completed Start and End Dates: July 1, 2023 to October 31, 2023 Description: - Implement the reinforcement learning based rate adaptation algorithm in Wi-Fi wireless networks in the ns-3 network simulator - Implement the adversarial machine learning attack model in WiFi wireless networks in the ns-3 network simulator Baseline:Models are not implemented Activities: We have implemented the ReinRate algorithm and the adversarial machine learning attack model on the ns-3 network simulator. Outcomes: The implementations of the ReinRate algorithm and the adversarial attack model will be used to run evaluation experiments. |
| Indicator: Wi-Fi experiments Status: Completed Start and End Dates: October 1, 2023 to December 31, 2023 Description: - Run extensive experiments on the ns-3 network simulator to evaluate the performance of the ReinRate algorithm and quantify the efficacy of the adversarial machine learning attack in Wi-Fi wireless networks Baseline:No experiments conducted yet. Activities: We have conducted experiments on the ns-3 simulator to evaluate the performance of the ReinRate algorithm and the impact of the adversarial attack on the Wi-Fi network performance. Outcomes: Extensive simulations on the ns-3 network simulator show that our ReinRate algorithm consistently outperforms the traditional Minstrel and Ideal rate adaptation algorithms by up to 102.5% and 30.6% higher network throughput in network scenarios without interference, and by up to 35.1% and 66.6% in network scenarios with interference. Our experimental results showed that the RL-based adversarial attack can reduce the network throughput to a lower, targeted throughput level,and at at the same time, used up to 19.6% less jamming packets to achieve the task compared to a simple heuristic attack. This indicates the RL-based adversarial attack is more energy efficient and is less likely to be detected, compared to the heuristic attack. |
Project Review and Assessment
We have conducted an extensive literature survey on the applications of reinforcement learning (RL) to the Wi-Fi rate adaptation algorithms. Understanding how these RL-based rate adaptation algorithms work has been crucial to our design of an adversarial machine learning attack model that seeks to negatively impact the performance of the RL-based algorithms in Wi-Fi networks. We have designed and implemented our own RL-based rate adaptation algorithm (named ReinRate) on the ns-3 network simulator, and have evaluated its performance in a variety of network scenarios and compared its performance to the state-of-the-art Minstrel rate adaptation algorithm. Our experimental results showed that ReinRate consistently outperforms Minstrel in network scenarios with and without interference, and is able to quickly adapt to dynamic changes in channel conditions.
We have also conducted a literature review on adversarial machine learning attacks in wireless networks, and have designed and implemented an RL-based adversarial attack model and evaluated its impact on the ReinRate rate adaptation algorithm on the ns-3 network simulator. Our experimental results showed that the RL-based adversarial attack can reduce the network throughput to a lower, targeted throughput level, and at at the same time, used up to 19.6% less jamming packets to achieve the task compared to a simple heuristic attack. This indicates the RL-based adversarial attack is more energy efficient and is less likely to be detected, compared to the heuristic attack.
We have made available the source code of our implementations of the ReinRate rate adaptation algorithm and the RL-based adversarial attack algorithm on the GitHub platform. We have also written a paper on our ReinRate work, which will be presented at the 2024 IEEE Wireless Communications and Networking Conference (WCNC). We are currently writing a paper on our results from the RL-based adversarial attack. Our hope is that other researchers in the world will use and extend our work to develop new reinforcement learning-based algorithms in the Wi-Fi wireless networks. For future work, we intend to design and develop effective detection methods of adversarial attacks and counter-measures against them in Wi-Fi wireless networks.
Unfortunately due to time limitations, we did not manage to complete the implementation of the proposed models and algorithms in the software-defined radio (SDR) testbed. We have purchased the SDR hardware, setup a testbed and performed some experiments to investigate the Wi-Fi support capabilities of the SDR hardware. In the process of this investigation, we realized that it would require considerable effort and time to implement the proposed RL models on the SDR platform and as a result, made the decision to pivot to the ns-3 network simulator where implementation work would be more effective and it is also easier to evaluate the performance of the RL models. With the ns-3 network simulator, we were able to evaluate the performance of the RL models in a variety of network scenarios, which would have been challenging to achieve in the SDR testbed. Having said that, we intend to continue with the implementation work on the SDR testbed, and will share our results with the wider networking community through open-source code release and technical publications.
Diversity and Inclusion
The project team includes a female academic Associate Professor Hui Tian, who has contributed towards the design of the adversarial machine learning attack model on the ReinRate rate adaptation algorithm.
Project Communication
We have written a paper on the ReinRate rate adaptation algorithm which has been accepted and will be presented in the 2024 IEEE Wireless Communications and Networking Conference (WCNC) in Dubai. The paper is titled "A Reinforcement Learning Approach to Wi-Fi Rate Adaptation Using the REINFORCE Algorithm" and will be available for download from IEEE Xplore digital library. We are currently writing a paper on our results from the RL-based adversarial attack. The code base developed in this project (both the ReinRate and adversarial attack works) are available for download on GitHub:
to enable other researchers in the world to extend on our work and further the knowledge development on reinforcement learning models as applied to Wi-Fi wireless networks.
Project Sustainability
Unfortunately due to time limitations, we did not manage to complete the implementation of the proposed models and algorithms in the software-defined radio (SDR) testbed. We intend to continue with the implementation work on the SDR testbed, and share our results with the wider networking community through open-source code release and technical publications. We also intend to continue working on this project in terms of designing new adversarial attacks and defense mechanisms against these attacks. This will be offered as Honours/PhD research projects to students in our university.
Project Management
We engaged a research assistant (RA) at 0.6FTE in April 2023 to work on the project. We worked closely with the RA to design, implement and evaluate (using the ns-3 simulator) the performance of the following algorithms:
- a reinforcement-learning based Wi-Fi rate adaptation algorithm called ReinRate
- a reinforcement-learning based adversarial attack on the ReinRate algorithm
We have also purchased four USRP B210 SDR kit to setup a software-defined radio (SDR) wireless testbed that will be used to evaluate the performance of the ReinRate algorithm and the RL-based adversarial attack on the rate adaptation algorithm. Unfortunately due to time limitations, we have not completed the implementation in the SDR wireless testbed. We plan to continue our implementation work on the SDR testbed, and share our results with the wider networking community through open-source code release and technical publications.
Project Recommendations and Use of Findings
Traditional rate adaptation algorithms such as the Minstrel algorithm typically rely on a limited number of observations such as packet loss rate or Signal-to-Noise Ratio (SNR). In contrast, our proposed ReinRate algorithm incorporates as input a broader set of observations, including received signal strength, contention window size, current MCS, and throughput. This comprehensive view allows for a more nuanced response to varying network conditions. To ensure the algorithm’s efficiency, the reward function is formulated using the difference in the current network throughput from its theoretical maximum. ReinRate is able to learn and determine the optimal MCS that minimizes the observed reward, thereby achieving maximal network throughput. Extensive simulations on the ns-3 network simulator show that our ReinRate algorithm consistently outperforms the traditional Minstrel and Ideal rate adaptation algorithms by up to 102.5% and 30.6% higher network throughput in network scenarios without interference, and by up to 35.1% and 66.6% in network scenarios with interference.
In this project, we have also designed a novel adversarial attack strategy on the ReinRate rate adaptation algorithm. The objective of the adversarial attack is to negatively impact the reward of the ReinRate RL agent at the victim node, and hence trick the victim node’s ReinRate RL agent to select a non-optimal data rate for its future transmissions. As a result, these adversarial attacks will cause the network throughput performance to drop to a targeted throughput level. The adversarial attack strategy is based on the REINFORCE reinforcement learning algorithm, and intelligently decides when to send a jamming packet to interfere with the victim node's transmissions. The decision to attack or remain passive is based on the current network state incorporating metrics like the current network throughput, targeted throughput level, the current MCS encoding and the number of jamming packets sent per second. This ensures that the RL-based attack can effectively disrupt the victim node's transmissions while at the same time, minimize its own exposure and energy consumption. We have evaluated the performance of the RL-based attack and a simple heuristic attack approach in both static and mobile scenarios. The experimental results show that while both the simple heuristic attack and the RL-based attack can reduce the network throughput to the targeted throughput level, the RL-based attack uses up to 19.6% less jamming packets to achieve the task, thereby indicating that the RL-based attack is more energy efficient and is less likely to be detected, compared to the heuristic attack.
For the Internet industry in general, and wireless network operators in particular, our two pieces of work in this project have shown the effectiveness and viability of machine learning, in particular, reinforcement learning, in the design of algorithms to optimize wireless network operations as well as in the design of adversarial attacks on the operations of network algorithms in wireless networks. The work in this project will help to better understand the vulnerabilities of machine learning to adversarial attacks and lead to the development of effective detection methods of adversarial attacks and counter-measures against them in wireless networks.
We have written a paper on the ReinRate rate adaptation algorithm which has been accepted and will be presented in the 2024 IEEE Wireless Communications and Networking Conference (WCNC) in Dubai. The paper is titled "A Reinforcement Learning Approach to Wi-Fi Rate Adaptation Using the REINFORCE Algorithm" and will be available for download from IEEE Xplore digital library. We have also made available the source code of our implementations on GitHub in order to enable other researchers in the world to extend on our work and further the knowledge development on reinforcement learning models as applied to Wi-Fi wireless networks.
Bibliography
[1] D. Xia, J. Hart, and Q. Fu, “Evaluation of the Minstrel rate adaptation algorithm in IEEE 802.11g WLANs,” in 2013 IEEE International Conference on Communications (ICC). IEEE, 2013, pp. 2223–2228.
[2] F. Fietkau, “Minstrel_HT: New rate control module for 802.11n.” [Online]. Available: https://lwn.net/Articles/376765/
[3] R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,” Machine learning, vol. 8, pp. 229–256, 1992.
[4] “ns-3: ns3::idealwifimanager class reference.” [Online]. Available: https://www.nsnam.org/docs/release/3.35/doxygen/ideal-wifi-manager_8cc.html
[5] W. Lin, Z. Guo, P. Liu, M. Du, X. Sun, and X. Yang, “Deep reinforcement learning based rate adaptation for Wi-Fi networks,” in 2022 IEEE 96th Vehicular Technology Conference (VTC2022-Fall). IEEE, 2022, pp. 1–5.
[6] F. Geiser, D. Wessel, M. Hummert, A. Weber, D. Wu¨bben, A. Dekorsy, and A. Viseras, “DRLLA: Deep reinforcement learning for link adaptation,” in Telecom, vol. 3, no. 4. MDPI, 2022, pp. 692–705.
[7] S. Cho, “Reinforcement learning for rate adaptation in CSMA/CA wireless networks,” in Advances in Computer Science and Ubiquitous Computing: CSA-CUTE 2019. Springer, 2021, pp. 175–181.
[8] R. Queiro´s, E. N. Almeida, H. Fontes, J. Ruela, and R. Campos, “Wi-Fi rate adaptation using a simple deep reinforcement learning approach,” in 2022 IEEE Symposium on Computers and Communications (ISCC). IEEE, 2022, pp. 1–3.
[9] S.-C. Chen, C.-Y. Li, and C.-H. Chiu, “An experience driven design for IEEE 802.11ac rate adaptation based on reinforcement learning,” in IEEE INFOCOM 2021-IEEE Conference on Computer Communications. IEEE, 2021, pp. 1–10.
[10] H. Yin, P. Liu, K. Liu, L. Cao, L. Zhang, Y. Gao, and X. Hei, “ns3-ai: Fostering artificial intelligence algorithms for networking research,” in Proceedings of the 2020 Workshop on ns-3, 2020, pp. 57–64.
[11] T. Erpek, Y.E. Sagduyu, and Y. Shi, “Deep learning for launching and mitigating wireless jamming attacks,” IEEE Transactions on Cognitive Communications and Networking, vol. 5, no. 1, March 2019.
[12] Shi, Yi, et al. "How to attack and defend NextG radio access network slicing with reinforcement learning." IEEE Open Journal of Vehicular Technology 4 (2022): 181-192.
[13] Wang, Feng, et al. "Adversarial jamming attacks and defense strategies via adaptive deep reinforcement learning." arXiv preprint arXiv:2007.06055 (2020).
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License 

